 音声でブラウザを操作するプログラムを作成したので作り方を紹介します。
音声でブラウザを操作するプログラムを作成したので作り方を紹介します。
以前に作った音声入力で文章作成するプログラムと
ブラウザを操作する RPA のプログラムを使って作成しました。
考え方としては、Tkinter で作成した画面のボタン操作を認識した音声で置き換えます。
ブラウザの操作は、pywinauto を使用します。
音声認識は、SpeechRecognition を使用して作成した voice_input_GSR モジュールを使用します。
voice_input_GSR モジュールでは、Google Speech Recognition を
SpeechRecognition の音声認識エンジンとして使用しています。
pywinauto の基本的な使い方、pywinquto を使用したブラウザの操作、音声入力の仕方は、別記事で詳しく説明しています。
それらのリンクも載せておきますので興味があればご覧ください。
目次
- ◆アプリのサンプル画像と機能・特長
- ◆pywinautoの基本的な使い方
- ◆pywinautoでブラウザを操作する方法
- ◆音声入力する方法
- ◆音声認識のために変更した部分
- ◆voice_input_GSR モジュールについて
- ◆ソースの取得
- ◆アプリの取得
- ◆さいごに
◆アプリのサンプル画像と機能・特長
 ▷アプリ起動後の画面
▷アプリ起動後の画面
【機能・特長】
- ブラウザ(Chrome と Firefox)を操作できます
- 一つのタブを選択して操作します
- 次の操作を提供
- スクロール(上下)
- 先頭、末尾へ移動
- 次のリンクへカーソル移動
- 戻るボタン
- リンク先を表示
- タブを閉じる
- はてなブログ グループサイトの「次のリンク」ボタンに対応
- ページ内の検索を提供
- 音声認識での操作を提供
【考え方】
ベースにしているボタンでブラウザを操作するアプリに対して、
音声で、ボタンをクリックしたのと同等の操作を実行します。
- 音声入力で作成したモジュールをライブラリとして使う
- 音声を認識して該当するボタンを探す
- ボタンが見つかればボタンと同じ動作をする
- 音声認識の結果と操作したボタンが分かるようにする
プログラムの作り方について知りたい方は次へ
早速、アプリを使ってみたい方はこちらへ「アプリの取得」
◆pywinautoの基本的な使い方
▶pywinauto の基本的な使い方は、こちらの記事を参照してください。
📖 pywinautoでRPA(自動化)◇導入編【Python】 🔗
説明している内容は次の通りです。
【pywinautoの基礎】
- バックエンド
- エントリーポイント
- Applicationオブジェクトでは接続が必要
- ダイアログとコントロール
- ダイアログの指定方法
- コントロールの指定方法
- find_elementsメソッドのキーワード引数
【待機】
◆pywinautoでブラウザを操作する方法
▶pywinauto でブラウザを操作する方法は、こちらの記事を参照してください。
📖 pywinautoでRPA(自動化)◇ブラウザ編【Python】 🔗
説明している内容は次の通りです。
【タブブラウザの特徴を理解する】
【ブラウザを操作する】
◆音声入力する方法
▶音声入力する方法は、こちらの記事を参照してください。
📖 音声入力で文章作成するアプリの作り方【Python】🔗
説明している内容は次の通りです。
- SpeechRecognition の基本的な使い方を説明しています
以上の参照記事では、voice_input_GSR モジュールの説明がありません。
本記事に追加したので参照してください。
※今回、voice_input_GSR モジュールをライブラリとして呼ぶために変更しています。
◆音声認識のために変更した部分
本プログラムは、記事『pywinautoでRPA(自動化)◇ブラウザ編【Python】 🔗』で紹介したソースをベースにしています。
ここでは、そのソースに追加、変更した部分を説明します。
◇音声入力プログラムをライブラリとして使用
音声認識を実現するために、以前に作成した音声入力するプログラム(音声入力で文章作成するアプリの作り方【Python】🔗)をライブラリとして使用します。
そのために音声入力のプログラムをパッケージ化しました。
- パッケージ名:voice_input_juu7g
- モジュール名:voice_input_GSR
パッケージ化されたライブラリをインストール、インポートして使用できるようにします。
【処理】
パッケージ化した音声入力プログラムを pip でインストールします。 プログラム上では次のようにインポートします。
- インストール:
pip install git+https://github.com/juu7g/Python-voice-input.git - インポート:
from voice_input_juu7g import voice_input_GSR
【コード】
from voice_input_juu7g import voice_input_GSR as myvr
# ...中略
self.vr = myvr.VoiceRecognizer()
◇音声操作の可視化
【処理】
音声認識して、どのボタンの操作が実施されているか分かるように、
操作中にボタンの背景色を変えます。
【コード】
▽RPA4Browser クラス(制御クラス)
音声認識かどうかにかかわらずボタンの操作をする時に背景を変えます
def key_type(self, event=None, key:str=None): """ ブラウザにキー操作を施す 操作中のボタンの背景色を変える Args: str: キーストローク名(key_stroke辞書のキーのどれか) """ if self.view: self.view.set_btn_bg_color(key, True) # ボタンの背景色を操作中の色に設定 # キー入力用辞書(キーストローク名:入力するキー) key_stroke = {"bottom":"{END}", "top":"{HOME}", "down":"{PGDN}", "up":"{PGUP}" , "next_page":"次のページ", "search":"検索", "jump":"{TAB}" , "back":"%{LEFT}", "see":"~", "close":"^w"} logger.info(f">>>start typing keys:{key}") if key == "next_page": self.search_word(key_stroke.get(key)) self.key_type(key="see") elif key == "search": self.search_word(self.view.var_word.get()) else: self.browser_dlg.type_keys(key_stroke.get(key)) self.browser_dlg.wait("ready") # type_keysの動作が終わるのを待つ これをしないとfocus_force()が先に動いてしまう self.view.focus_force() # 自分自身にフォーカスを戻す # ボタンが押されてこの処理に来た時は、マウスカーソルをボタンに戻す if event: event.widget.focus_set() self.view.event_generate("<Motion>", warp=True, x=event.widget.winfo_x()+10, y=event.widget.winfo_y()+10) if self.view: self.view.set_btn_bg_color(key, False) # ボタンの背景色を未操作の色に設定
▽MyFrame クラス(画面操作クラス)
def set_btn_bg_color(self, key:str, in_act:bool): """ ボタンの背景色を設定する """ _colors = {False:"SystemButtonFace", True:"lightgreen"} self.buttons[key].config(bg=_colors[in_act]) self.buttons[key].update_idletasks()
◇音声入力とボタン操作の割り付け
画面表示しているボタンの表示している文字列を認識して、 そのボタンに割り付いている操作を実施します。
【処理】
- 画面で使用しているコマンド用辞書をキーと値を入れ替えて辞書にする
- 「終わり」用の要素を辞書に追加する
- 「音声認識」ボタンの背景をオン状態にする
- 以下を繰り返す
- 音声認識を起動
- 結果を取得
- 認識した文字列がコマンド用辞書に含まれているかチェック
含まれている場合- 認識した文字が「終わり」なら繰り返しを終了
- コマンドを実施
- 認識した文字列の末尾が「を検索」かチェック
そうである場合- 認識した文字列の「を検索」より前の文字列を取得
- コマンドの検索を実施
- 「音声認識」ボタンの背景を元に戻す
【コード】
▽音声認識処理
Tkinter が止まらないようにスレッドを作成します。
def voice_ctl_th(self, event=None): """ voice_ctl用スレッド """ th = threading.Thread(target = self.voice_ctl, args=(event,), daemon=True) th.start()
▽音声を認識してコマンドを実施します
def voice_ctl(self, event=None): """ 音声を認識してコマンドを出す 「終わり」と認識するまで続ける """ # 画面で使用しているコマンド用辞書をキーと値を入れ替えて辞書にする cmd_dic = {v:k for k,v in self.view.commands.items()} cmd_dic["終わり"] = "OWARI" self.view.btn_voice.config(bg="lightgreen") self.view.btn_voice.update_idletasks() while True: self.vr.listen_voice(1) # 音声認識を起動 voice_cmd = self.vr.futures[-1].result() # 認識した音声を文字で取得 self.view.var_voice.set(voice_cmd) logger.info(f"認識文字:{voice_cmd}") if voice_cmd in cmd_dic: if voice_cmd == "終わり": break self.key_type(key=cmd_dic[voice_cmd]) if voice_cmd.endswith("を検索"): self.view.var_word.set(voice_cmd.rstrip("を検索")) self.key_type(key=cmd_dic["検索"]) self.view.btn_voice.config(bg="SystemButtonFace") self.view.btn_voice.update_idletasks()
▽画面に音声認識用のボタンを追加
class MyFrame(tk.Frame): """ 操作画面クラス """ def __init__(self, master) -> None: ... 中略 # 制御用ボタンの作成 self.commands = {"down":"下に", "next_page":"次のページ", "up":"上に" , "top":"一番上に", "bottom":"一番下に", "jump":"次のリンク" , "back":"戻る", "see":"表示", "close":"閉じる", "search":"検索"} self.buttons = {} for key, value in self.commands.items(): self.buttons[key] = tk.Button(self, text=value) self.buttons[key].bind("<1>", lambda event, key=key: self.rpa.key_type(event, key)) self.buttons[key].bind("<space>", lambda event, key=key: self.rpa.key_type(event, key), add=True) self.buttons[key].bind("<Return>", lambda event, key=key: self.rpa.key_type(event, key), add=True) self.buttons[key].pack(fill=tk.X) # 検索ボタンとエントリーの作成 self.buttons["search"].pack(pady=(5,0)) self.var_word = tk.StringVar(value="") ent_word = tk.Entry(self, textvariable=self.var_word) ent_word.pack(fill=tk.X) # 音声認識ボタンと認識内容表示ラベルの作成 self.btn_voice = tk.Button(self, text='音声認識') self.btn_voice.pack(fill=tk.X) self.var_voice = tk.StringVar(value="") lbl_voice = tk.Label(self, textvariable=self.var_voice) lbl_voice.pack(fill=tk.X)
◇マイクが準備できていない時の処理
マイクが準備できていない場合、voice_input_GSR モジュールの VoiceRecognizer クラスのコンストラクタが例外を出します。
それを判断して「音声認識」ボタンを不活性にします。
また、ボタンにバインドするメソッドも判断後に登録します。
【処理】
VoiceRecognizer クラスのコンストラクタの割り込みをキャッチして、
例外の場合、「音声認識」ボタンを不活性にします。
そうでない場合に「音声認識」ボタンに音声認識の処理をバインドします。
【コード】
▽RPA4Browser クラスのコンストラクタ
def __init__(self, view:tk.Frame) -> None: ... 中略 try: self.vr = myvr.VoiceRecognizer() except Exception as e: self.view.btn_voice.config(state='disable') else: self.view.btn_voice.bind('<1>', self.voice_ctl_th)
◆voice_input_GSR モジュールについて
voice_input_GSR モジュールをパッケージ化しました。
voice_input_juu7g パッケージとして GitHub からもインストールできます。
voice_input_GSR モジュールは、単独でもアプリとして動作しますが、ここではライブラリとして使用しています。
ライブラリとして使用する場合のモジュールの仕様を説明します。
◇インストール
- インストール:
pip install git+https://github.com/juu7g/Python-voice-input.git
GitHub から直接インストールできます
依存関係にあるパッケージも併せてインストールされます
※pyaudio がインストールできない場合、こちら(『pyaudioのインストール』)を参照してください。 - インポート :
from voice_input_juu7g import voice_input_GSR
◇VoiceRecognizerクラス
voice_input_GSR モジュールにある音声認識のためのクラスです。
◎コンストラクタ
- 【構文】
VoiceRecognizer(my_frame=None) -> None
Frame を使用してメッセージを出力する場合は Frame を指定します - 引数
- 例外
- マイクが認識できない場合、例外が発生します
◎メソッド
ライブラリとして使用する場合に使われるであろうメソッドを紹介します。
【listen_voice】
音声を聞いて音声データを作成します。
聞き終わったら音声認識をスレッドで呼び出します。
結果は futures 属性から取得します。
- 【構文】
listen_voice(i:int) - よく使う使い方(サンプル)
【構文】listen(1) - 引数
i:番号(処理の順番が分かるようにメッセージ出力用に用意)
- 戻り値:なし
ただし、音声認識の結果は futures 属性を参照して取得 - 記録開始:オーディオの大きさが
r.energy_threshold属性値を超える(ユーザーが話し始めた)までは待機
※r.energy_threshold属性値のデフォルトは、300
ただしdynamic_energy_threshold(デフォルトは有効)が有効なら自動調節 - 記録終了:
pause_threshold秒(デフォルトは0.8秒)の無音と判断する状態が発生するか、
オーディオ入力がなくなると終了
【mic_init】 Recognizer オブジェクトの音声認識のしきい値を設定します
- 【構文】
mic_init(is_dynamic:bool=False, threshold:int=50) - 引数
- 戻り値:なし
◎属性
futures:
音声認識をスレッドプールで実行した結果の Future オブジェクトがリストで返ります
リストは依頼順に並んでいます
Future オブジェクトのresult()メソッドを実行すると認識した文字列を取得できます
◆ソースの取得
全体のソースはこちらから取得できます。
- ソース:RPA_browser_with_voice.py
- 取得先:GitHub juu7g/Python-RPA
※ソースにはデバッグ用のコードが含まれていますのでご容赦ください。
デバッグには logging モジュールを使用しています。
logging モジュールの使い方については、別の記事で解説する予定です。
◆アプリの取得
アプリは、Chrome または Firefox で表示されているサイトのブラウジングを制御するものです。
はてなブログのグループサイト用に「次のページ」ボタンを押すためのボタンを用意しました。
ページ内のスクロールや検索ができます。
利用するには、アプリを含んだ zip ファイルを下記からダウンロードして取得します。
ダウンロードした zip ファイルを解凍すると次のファイルができます。
任意のフォルダにファイルを保存してください。
- プログラム:
RPA_browser_with_voice.exe
◇アプリの使い方
インストール
- ダウンロードした zip ファイルを任意のフォルダで解凍します
実行
- RPA_browser_with_voice.exe を実行します
操作
画面の説明
アンインストール
- 解凍したファイルをすべて削除します
サンプル画面
左:起動直後、「接続」ボタンをクリック
中:接続後、「音声認識」ボタンをクリック
右:「音声認識」ボタンが薄緑色になれば音声認識開始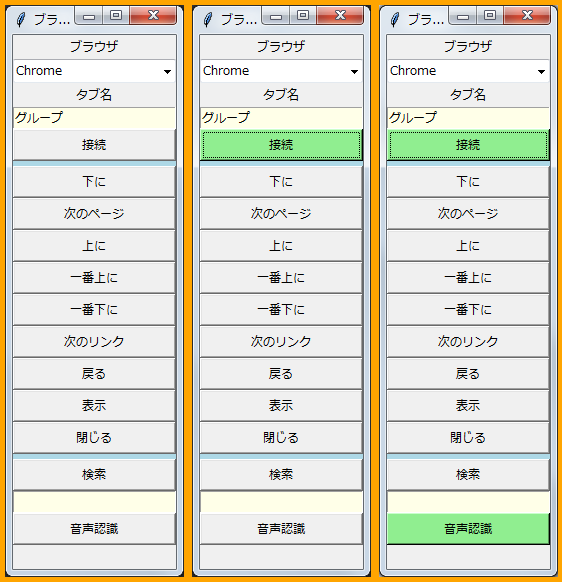
左:認識した音声を一番下に表示
中:「終わり」を認識すると音声認識を終了します
右:※マイクが見つからない時の画面
◆さいごに
今回は音声認識に Google Speech Recognition を利用したモジュール(voice_input_GSR.py)を使いました。
アプリにした場合、こちらの方が音声の認識率が高いためです。
アプリを使われる方がいるかどうかわかりませんが、自分でもあまり使わないので、もし使われるなら使い易い方をと考えました。
試しに使う分には面白いので、試していただけると幸いです。
スマートスピーカーもそうでしょうが、自分の声で動いてもらえると、「あっ、動いた」とほんの少しですが、喜べます。
もう一つ、CMU Sphinx を利用したモジュール(voice_input_Sphinx.py)も用意しています。
こちらはオフラインでも使用できるのが一番の特徴です。
しかし、私が適応したデータを配布して良いのかわからないこと、
私が適応したデータで誰の声でも認識できる(できるはず?)のかよくわからないこと、
などがあって、対応していません。
今回は音声といっても単語を認識して動作させているので簡単でした。
普通に話し言葉を認識しようとするとどうやればいいのかピンときません。
でも、既に実用化されている技術なので、何か方法があるのでしょう。
あまり深く入り込むと理解できないので・・・
◇ご注意
本記事は次のバージョンの下で動作した内容を基に記述しています。
- Python 3.8.5
- pywinauto 0.6.8
- SpeechRecognition 3.8.1
- PyAudio 0.2.11
- voice_input_juu7g 1.0.3
- Chrome 109.0.5414.120
- Firefox 109.0.1
◇免責事項
ご利用に際しては、『免責事項』をご確認ください。
お気づきの点がございましたら『お問い合わせ』からお問い合わせください。